Introduction
Setting up a RAG pipeline has traditionally been a challenge for most developers, as it requires configuring multiple components, including correctly chunking large documents, selecting and fine-tuning an embedding model, managing indexing logic, and, most importantly, choosing the proper vector database to store and retrieve embeddings efficiently. Each of these components introduces additional infrastructure, cost, and engineering overhead, making RAG feel far more complex than it needs to be for many real-world applications.
Google's Gemini API now provides a simplified way to adopt RAG through the File Search Tool, which automates the entire retrieval pipeline. File Search Tool in the Gemini API handles document ingestion, chunking, embedding, and indexing behind the scenes, eliminating the need to build our own embedding logic or choose a vector database. This allows developers to focus on building the application, not managing retrieval infrastructure.
In this blog, we'll walk through:
- What is File Search Tool
- How the File Search Tool Works Under the Hood
- How to upload and import files
- How to control chunking, metadata, and citations
- Getting started with File Search Tool - Python code
- Supported models for File Search Tool
- Rate limits and limitations
- Pricing for indexing and retrieval
- Managing File Search Stores
- Conclusion
1. What is the File Search Tool?
File Search Tool is a fully managed, built-in RAG capability in the Gemini API, designed to abstract the retrieval pipeline, allowing us to focus on building features rather than infrastructure.
At a high level, File Search Tool:
- Imports, chunks, and indexes our data automatically
- Uses semantic search to find relevant information for a prompt
- Provides that information as context to the model
- Enables the model to generate more accurate, grounded, and verifiable answers
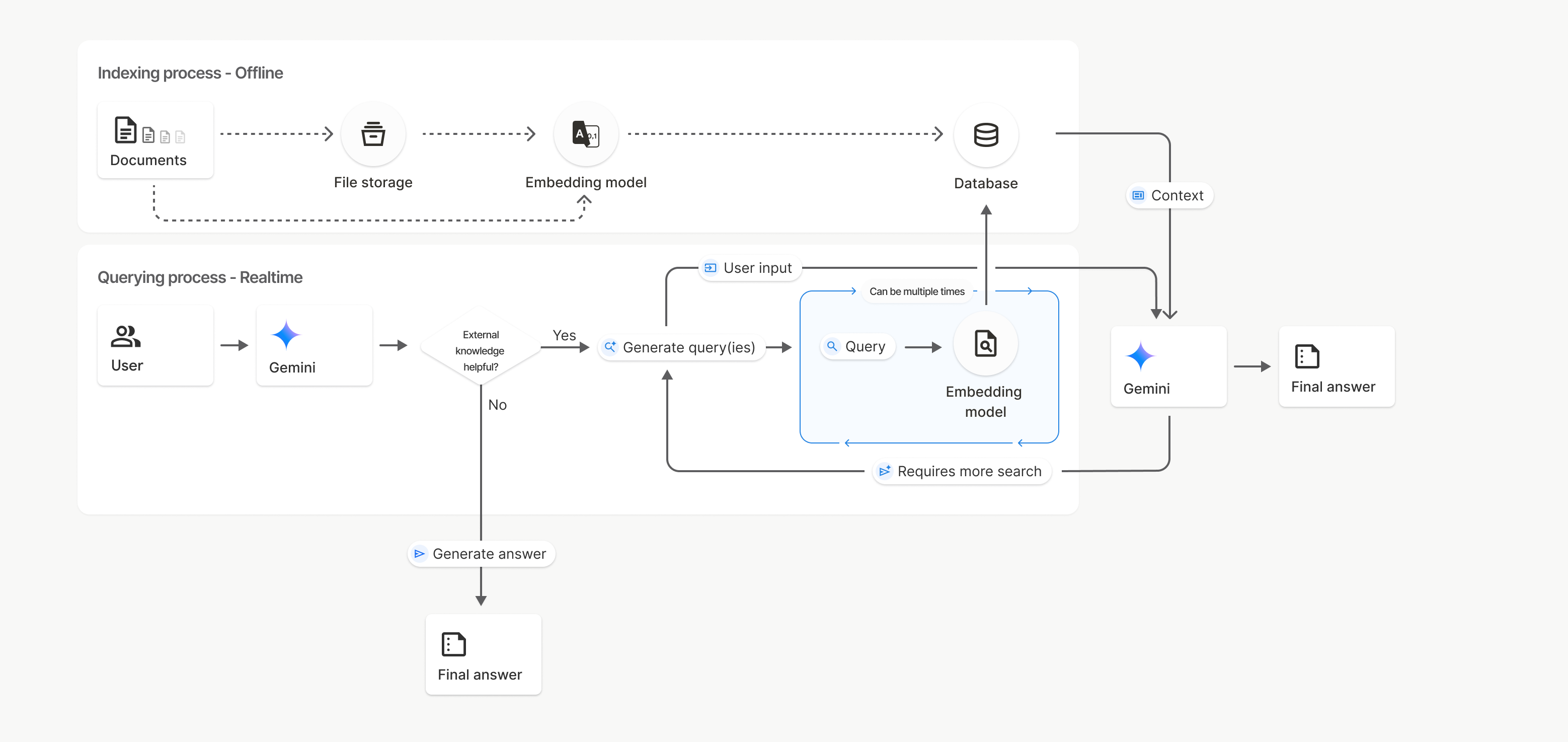
2. How File Search Tool Works Under the Hood
File Search Tool performs a semantic search rather than simple keyword matching, prioritizing the meaning and context of user queries over exact word matches. When we use the File Search Tool to import a file into the File Search database, it's converted into embeddings and indexed within the database. When we send a query, it's transformed into an embedding, and the most relevant chunks are selected as context. The File Search Tool is then used to generate a grounded answer.
Here's a high-level overview of how File Search Tool works:
1. Create a File Search store
A File Search store is a persistent container for our document embeddings. This is the semantic index that queries will search over.
2. Upload and import files
Uploaded documents are:
- Parsed and text is extracted
- Broken into coherent chunks
- Converted into embeddings
- Indexed in the File Search store
3. Issue a query
When we send a prompt:
- The query is converted into an embedding
- File Search Tool performs semantic similarity search across the store
- The most relevant chunks are selected as context
- Gemini uses that context to generate a grounded answer
4. Receive a grounded answer (with citations)
The response can include citations that show exactly which document chunks were used. This is critical when we care about traceability and correctness.
3. How We Can Upload and Import Files
File Search Tool provides two ways to bring documents into a store:
3.1 Direct Upload (uploadToFileSearchStore)
Uploads and processes a file in a single step, automatically handling chunking, embedding, and indexing.
from google import genai
from google.genai import types
import time
client = genai.Client()
# Create the File Search store with an optional display name
file_search_store = client.file_search_stores.create(config={'display_name': '2_Agent_Tools_and_Interoperability_with_MCP'})
# Upload and import a file into the File Search store, supply a file name which will be visible in citations
operation = client.file_search_stores.upload_to_file_search_store(
file='2_Agent_Tools_and_Interoperability_with_MCP.pdf',
file_search_store_name=file_search_store.name,
config={
'display_name': 'Agent Tools & Interoperability with Model Context Protocol (MCP)',
}
)3.2 Upload First → Import Later (importFile)
Uses the Files API to upload a document and then imports it into the File Search store. This approach is practical when attaching metadata or reusing files across multiple stores.
from google import genai
from google.genai import types
import time
client = genai.Client()
# Upload the file using the Files API, supply a file name which will be visible in citations
sample_file = client.files.upload(file='2_Agent_Tools_and_Interoperability_with_MCP.pdf',
config={'name': 'Agent Tools & Interoperability with Model Context Protocol (MCP)'},)
# Create the File Search store with an optional display name
file_search_store = client.file_search_stores.create(config={'display_name': '2_Agent_Tools_and_Interoperability_with_MCP'})
# Import the file into the File Search store
operation = client.file_search_stores.import_file(
file_search_store_name=file_search_store.name,
file_name=sample_file.name
)Once uploaded, files are transformed into searchable embeddings, ready for retrieval during model calls.
4. How to Control Chunking, Metadata, and Citations
File Search Tool automatically chunks documents, but we can override this with a chunking_config to fine-tune chunk sizes and overlap useful for technical documentation or source code.
We can also attach custom metadata (e.g., author, category, version) during import, enabling filtered retrieval using metadata expressions.
When queries are executed with File Search Tool enabled, Gemini includes citations in the response via grounding metadata. These citations show exactly which chunks of which documents were used, providing full transparency and traceability.
Chunking Configuration
When we import a file into a File Search store, it's automatically broken down into chunks, embedded, indexed, and uploaded to our File Search store. If we need more control over the chunking strategy, we can specify a chunking_config setting to set a maximum number of tokens per chunk and maximum number of overlapping tokens.
# Upload and import the file into the File Search store with a custom chunking configuration
operation = client.file_search_stores.upload_to_file_search_store(
file_search_store_name=file_search_store.name,
file='2_Agent_Tools_and_Interoperability_with_MCP.pdf',
config={
'chunking_config': {
'white_space_config': {
'max_tokens_per_chunk': 500,
'max_overlap_tokens': 100
}
}
}
)5. Getting Started with File Search Tool - Python code
To get started with File Search Tool, we will use the Google document from the 5-day intensive course on AI agents on Kaggle Agent Tools & Interoperability with Model Context Protocol (MCP) whitepaper as our example document.
- Create a File Search store - This store acts as the semantic index where all document embeddings and chunks are stored.
- Upload our documents to the store - We can either upload and import directly or upload first using the Files API.
- Configure the model to use File Search Tool as a tool - We attach our File Search store to the
generateContentrequest. - Query the model with our questions - Gemini retrieves relevant chunks and returns grounded answers.
Step 1: Create a File Search Store
The File Search store is our semantic index where all document embeddings are stored.
from google import genai
client = genai.Client()
# Create a File Search store with an optional display name
file_search_store = client.file_search_stores.create(
config={'display_name': 'Agent Tools & Interoperability with Model Context Protocol (MCP)'}
)
print(file_search_store.name)Step 2: Upload Documents to the Store
Next, we upload a document and import it into the File Search store so it can be chunked, embedded, and indexed.
import time
# Upload and import a file into the File Search store
operation = client.file_search_stores.upload_to_file_search_store(
file='2_Agent_Tools_and_Interoperability_with_MCP.pdf',
file_search_store_name=file_search_store.name,
config={'display_name': 'Agent Tools & Interoperability with Model Context Protocol (MCP)'}
)
# Wait for processing to complete
while not operation.done:
time.sleep(5)
operation = client.operations.get(operation)
print("File imported into File Search store.")Step 3: Configure File Search Tool as a Tool
We then configure File Search Tool as a tool so the Gemini model knows which File Search store to use for retrieval.
from google.genai import types
# Configure File Search Tool as a tool
file_search_tool = types.Tool(
file_search=types.FileSearch(
file_search_store_names=[file_search_store.name]
)
)Step 4: Query the Model with Our Questions
Finally, we send a question to the model. Gemini uses File Search Tool to retrieve relevant chunks and ground its response.
# Ask a question grounded on the uploaded document
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="What is MCP Server?",
config=types.GenerateContentConfig(
tools=[file_search_tool]
)
)
print(response.text)
# Print the grounding metadata
print(response.candidates[0].grounding_metadata)
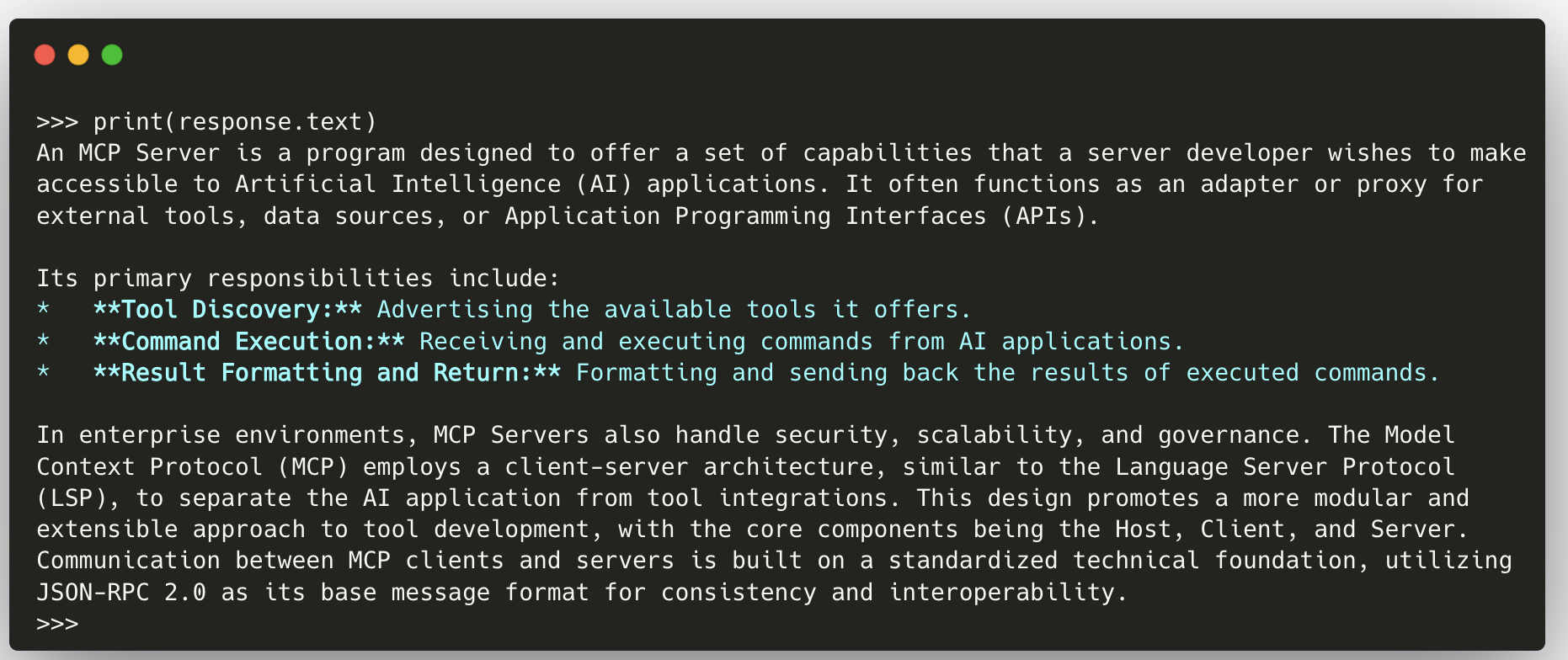
By separating these steps, we can clearly see how File Search Tool fits into our RAG pipeline: we create a store, upload documents, configure the tool, and then query the model with grounded questions.
6. Supported Models for File Search Tool
File Search Tool is supported by the latest Gemini models optimized for grounding and retrieval workflows:
- gemini-2.5-pro - High-quality reasoning and grounding for complex RAG workflows.
- gemini-2.5-flash - Cost-efficient, high-performance grounding for everyday applications.
Both models can access File Search stores and use retrieved chunks as context during generation.
7. File upload limits and limitations
File Search Tool enforces several limits to ensure stability:
- Maximum file size per document: 100 MB
- Total File Search store size per project:
- Free: 1 GB
- Tier 1: 10 GB
- Tier 2: 100 GB
- Tier 3: 1 TB
- Recommended store size: Keep each store under 20 GB for best retrieval latency
- Raw files uploaded via Files API are deleted after 48 hours, but embeddings in stores persist until manually deleted.
These limitations ensure predictable performance and efficient retrieval at scale.
8. Pricing for Indexing and Retrieval
File Search Tool uses a simple pricing model:
- Indexing cost: $0.15 per 1M tokens (embedding cost during ingestion)
- Storage cost: Free
- Query-time embeddings: Free
- Retrieved document tokens: Charged as standard context tokens for the model
This means most costs occur at ingestion time, and ongoing usage is primarily tied to model context token consumption.
9. Managing File Search Stores
1. Create a File Search store
# Create a File Search store (including optional display_name for easier reference)
file_search_store = client.file_search_stores.create(config={'display_name': 'Agent Tools & Interoperability with Model Context Protocol (MCP)'})2. List all your File Search stores
# List all your File Search stores
for file_search_store in client.file_search_stores.list():
print(file_search_store)3. Get a specific File Search store by name
# Get a specific File Search store by name
my_file_search_store = client.file_search_stores.get(name='fileSearchStores/agent-tools-interoperabilit-kvwplm87m3ta')4. Delete a File Search store (cleanup)
# Delete a File Search store (cleanup)
client.file_search_stores.delete(name='fileSearchStores/agent-tools-interoperabilit-kvwplm87m3ta', config={'force': True})
# Clean up: Delete all files in the store before deleting the store itself (optional)
# This ensures complete cleanup of all associated resources10. Conclusion
File Search Tool in the Gemini API simplifies Retrieval-Augmented Generation by removing many of the traditional barriers that make RAG complex. Instead of managing chunking logic, embedding pipelines, vector databases, and search infrastructure, we can now rely on a fully managed system that handles everything behind the scenes.
With automatic ingestion, chunking, embedding, indexing, semantic retrieval, and built-in citations, the File Search Tool provides us with all the necessary building blocks eliminating the need to own any retrieval infrastructure. We create a store, upload documents, attach File Search Tool as a tool, and start asking grounded questions.